第二次作业
详细作业代码参见 GitHub 仓库
Problem 1
Section titled “Problem 1”这是 Q leaning 的核心公式,其中右边括号里的是 TD error,表示新观察到的目标价值 和 旧估计值 之间的差距。
具体来说,代表学习率, 表示执行动作 之后得到的奖励,决定未来奖励的重要程度,而
表示到达下一个状态 后,假设会选择价值最高的那个动作。
使用固定的表格来记录所有的 Q 值,这是运行的结果:
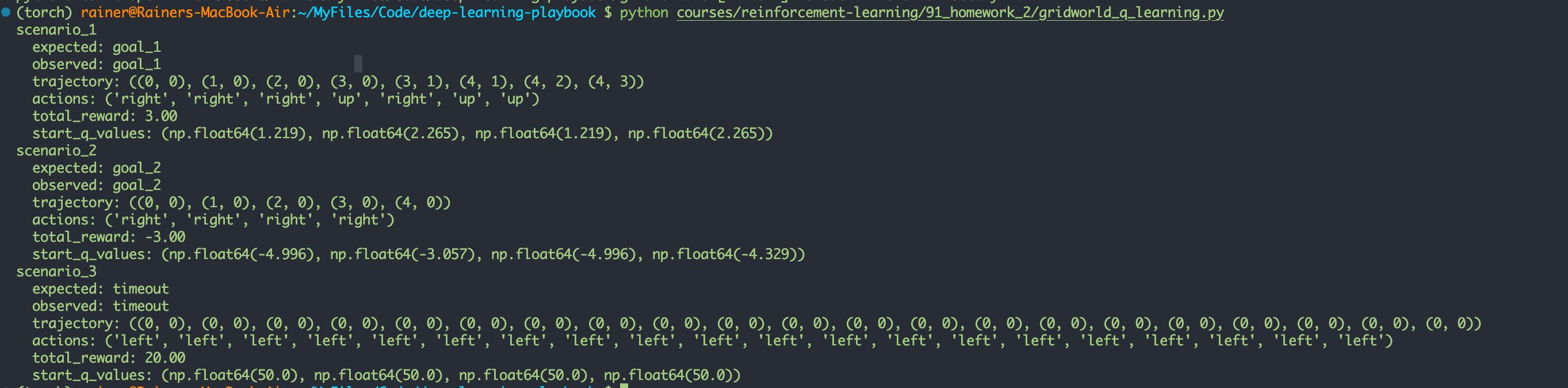
在这个项目中分别对应三种场景:
scenario_1:每走一步扣 1,但 goal 1 奖励更高,所以 agent 应该愿意多走几步去更远的 goal 1。scenario_2:每走一步扣 2,走路代价更大,所以虽然 goal 1 奖励高,agent 反而应该去更近的 goal 2。scenario_3:每走一步奖励 +1,两个 goal 只有 +1,进入 goal 会终止 episode,所以 agent 最优行为是拖着不进 goal,直到 timeout。
运行的结果也是符合这种行为的。
Problem 2
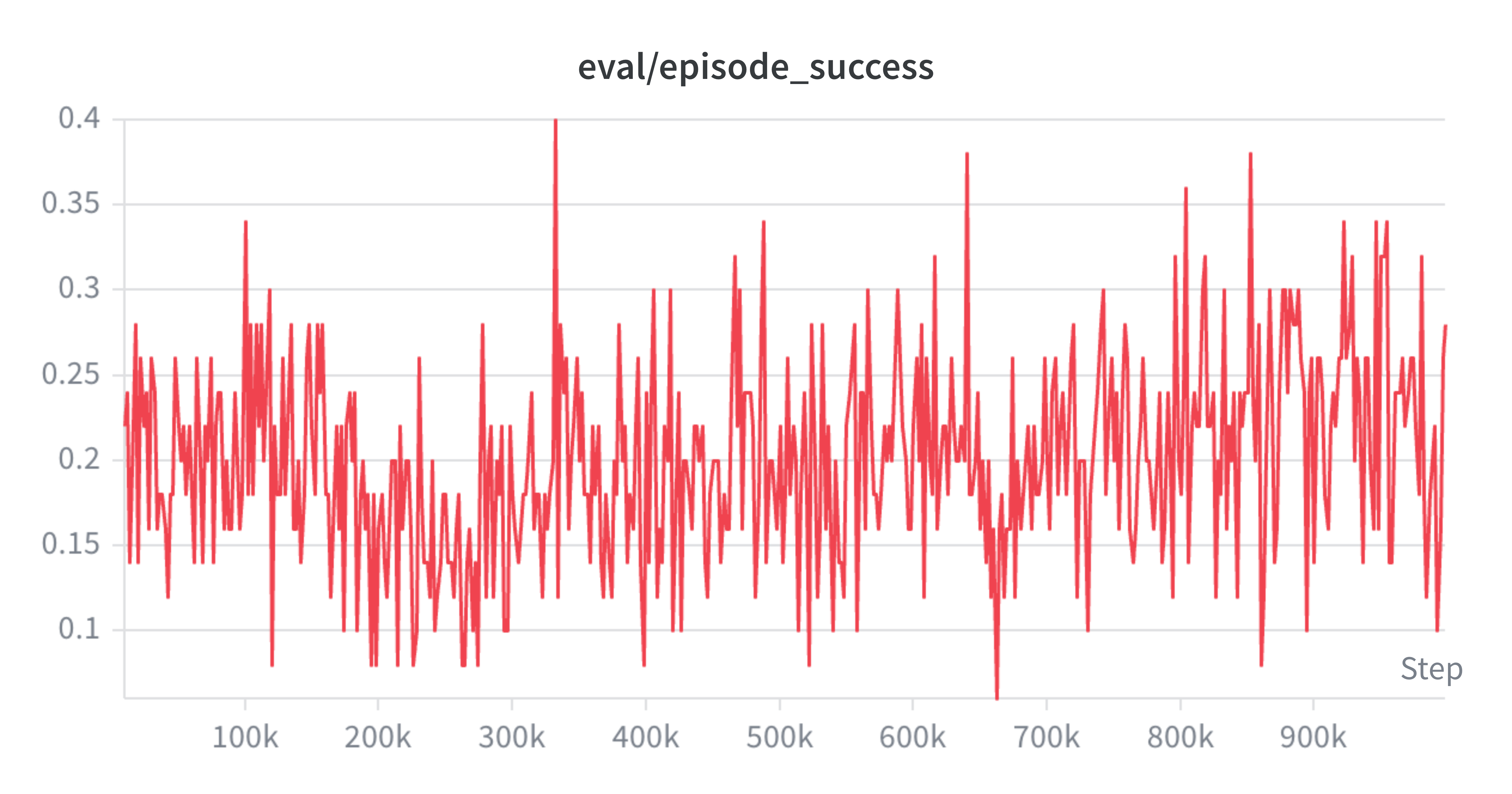
Section titled “Problem 2”本题目主要集中于部署 GAE 的 TE Error 算法以及 PPO 中的 clip 算法两大部分,也就是最核心的部分。
相关的理论部分可直接查看第 5 章离策演员评论家的内容,代码参照 GitHub 仓库,这里只放出结果。
这里是 W&B 训练的成功率截图,相对还是比较低的,后期大约在 20% 到 30% 的区间内,最好表现是 40% 左右