
02 模仿学习
02 模仿学习
Section titled “02 模仿学习”给定一个 expert 演示如何完成任务,例如人类在驾驶骑车的时候的一组数据。
模仿学习的目标就是去学习 expert 使用的 policy,让策略的行为和专家的行为最小化
这里的行为有点像普通的监督学习,正向传播拿到结果,随后通过结果来方向传播数据。
但实际上 expert 的数据不是确定的,例如一个场景,有可能有的司机会变道超车,但有的司机会直行。因此一个 expert 的数据实际上是一组分布(distribution),而不是一个确定的值。
如果使用 L2 loss 去预测一个双峰的分布,就会导致收敛到一个概率很小的不应该的位置。
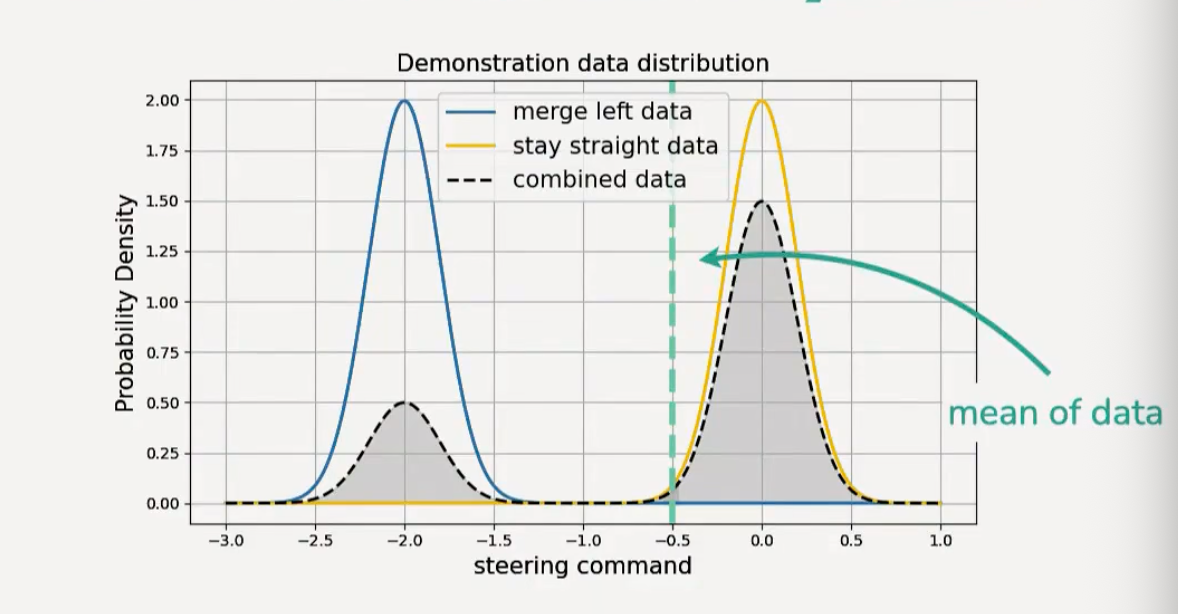
这是一个非常常见的现象,因此学习的目标不能够是均值,而是一个分布,通过神经网络学习分布。
解决方法就是,让神经网络输出的结果变成一组参数值,这代表了一组操作的分布。有时候操作的分类是离散的(确定的 n 组分类)但更多的时候会无法通过离散分类表示。
生成模型策略
Section titled “生成模型策略”在计算机中主要有三种方式去生成这种分布:第一个是通过分布参数控制,例如GMM(Gaussian Mixture Model,高斯混合模型):
用个权重,个数,等等离散的参数表示一个分布。
第二种方式就是离散化,类似于模拟信号转数字,通过采样分桶的方式来离散化整个分布。
第三种是扩散模型,擅长对复杂的操作进行模拟,具体分类参考下图:
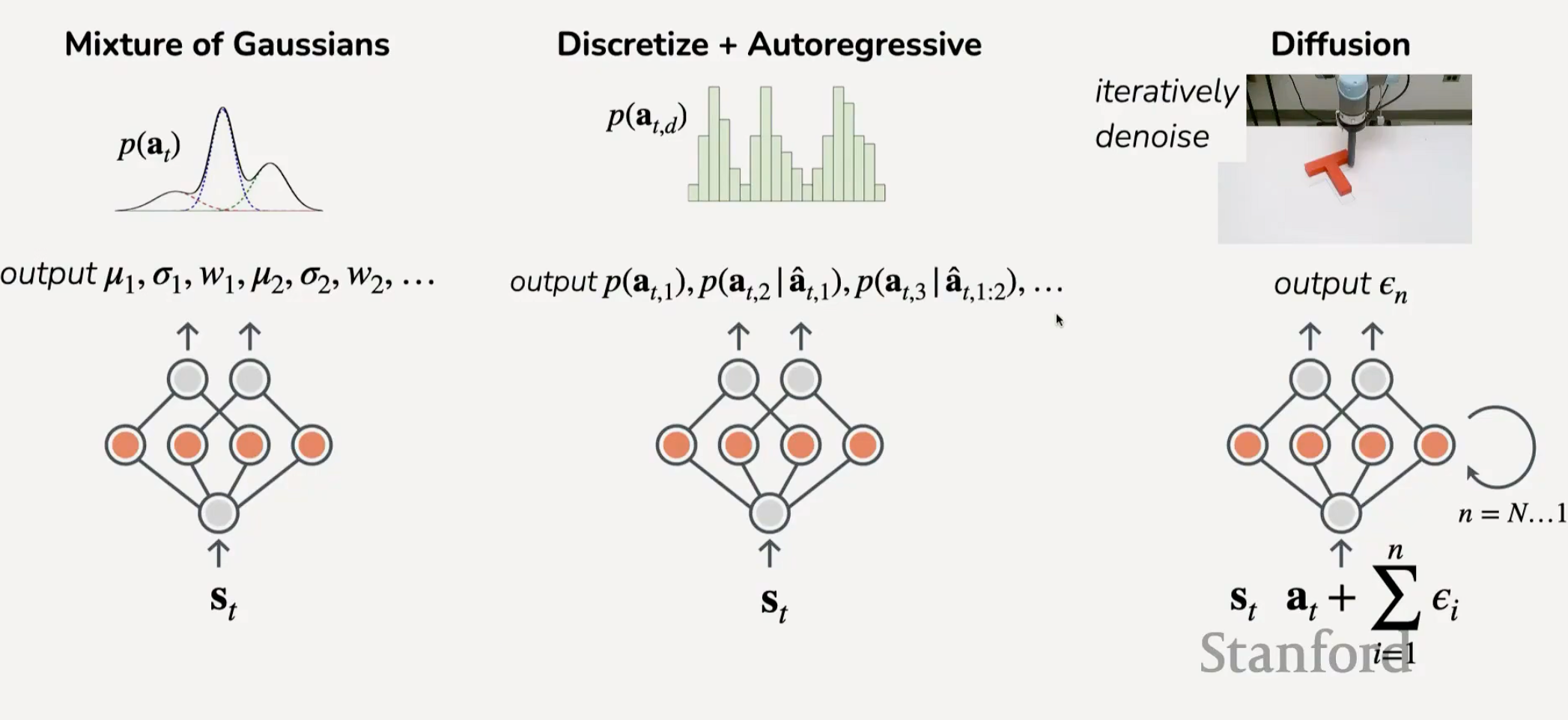
对于一个 给定输入的数据集 ,如何开始训练呢?
执行采样,随机抽取一组数据,训练目标是 (本质上就是最大似然估计 MLE)
这里的 表示的是参数为 的策略网络,在状态 下选择动作 的概率。一般来说对于离散的概率分布都是使用交叉熵 Softmax 那一套 Loss
完整生成模型的 Loss 表达如下,对应期望算法:
模仿学习和普通深度学习中分类任务的最大的区别,就是模仿学习的误差会影响后续状态分布。
当模仿学习的一步结果出现了错误,进入了一个数据集中很少见的 state,那么后面的所有的行为可能都会出现不合理的结果。
这个情况被称作为:covariate shift,模仿学习的难点也在于如何在出现误差后修正回来。这就需要收集修正误差的数据了。

一种方式(DAgger)就是,在 policy 偏离到一定程度的时候, expert 开始接入并获取完全控制,然后后续继续让 policy 学习这个策略。
这个缺点也是模仿学习算法最本质的缺点。