
01 深度强化学习基础
01 深度强化学习基础
Section titled “01 深度强化学习基础”本笔记基于 CS224R 课程
监督深度学习,是学习一种映射,让输入(例如数据集里独立的一个数据)经过映射后尽可能趋向于目标(也就是学习目标),
强化学习是学习一种行为 (也称作策略, policy ),常用在驾驶,机器人控制,游戏等,从 ”经验“ 中学习,逐渐趋向于目标。在 LLM 领域内常用的地方在于 RLHF,检查一个模型是否输出符合人类的习惯,是否指令遵循等等。
强化学习一个显著的特点在于,监督信号可能是存在的,但不是直接的输出,可能是间接的评价。例如,对于一个模型的输出结果,监督信号是 “好” 与 ”不好“,而不是模型应当输出什么的直接信号。
模型从 “经验” 中学习,为此我们需要表示这个内容,看起来有点像马尔可夫链:
- State: 世界状态,实际的状态
- Observation: 在时间点 上 agent 实际观测到东西
- Action: 模型选择做出的一个行为
- Trajectory: 上述三个组合起来得到的结果(轨迹),是一个序列的执行结果,也就是多个时间段下,观测/状态+行为的结果:
- Reward function: 奖励函数, 用来评判一个基于状态的行为的好坏
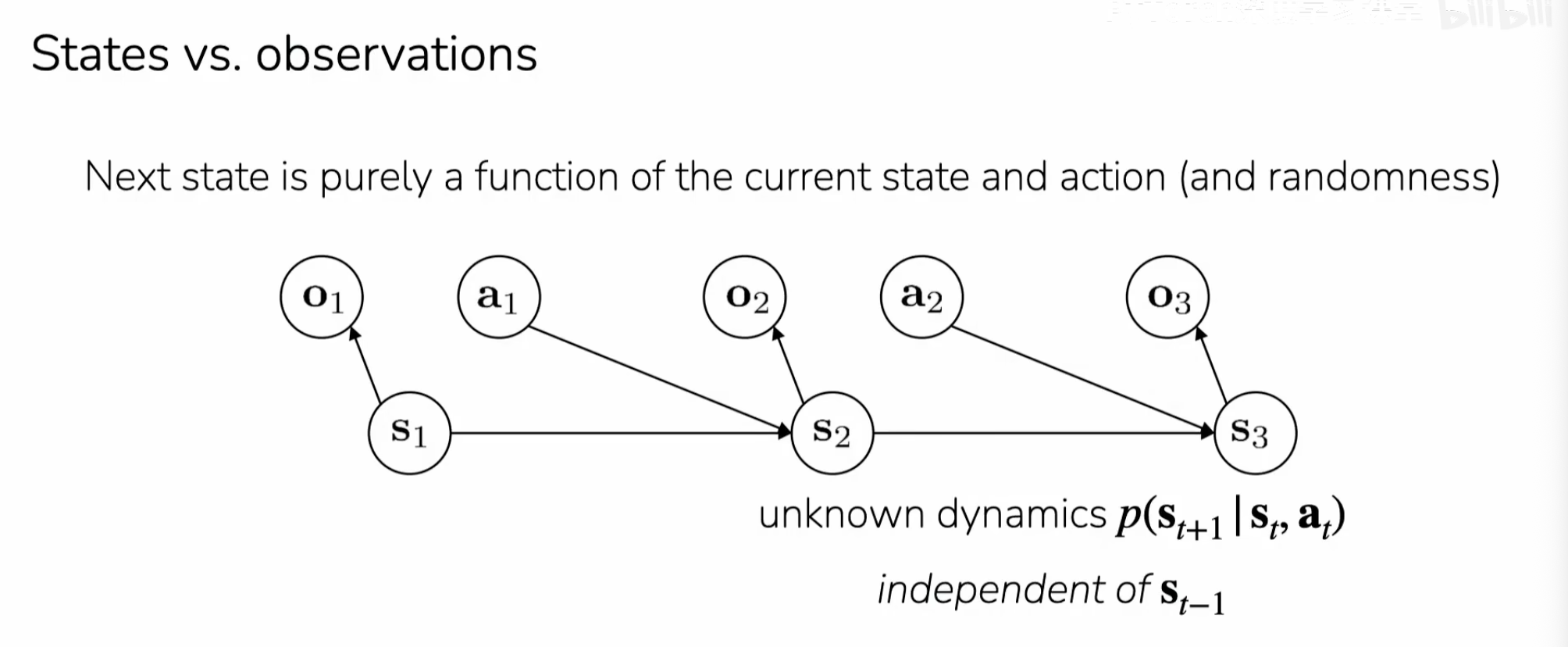
如图,模型的决策只跟当前的状态有关,与之前的状态无关,构成了马尔可夫性。
一般而言强化学习的目标是下式,注意这里实际上是期望,而不是直接求和,这是因为随机性导致每一次的决策都可能是不一样的,策略 的影响在于期望上
其中
不同于深度学习中的梯度下降,强化学习中有很多种类的算法,包括以下:
- Imitation learning:模仿学习
- Policy gradients:策略梯度
- Actor-critic:演员-评论家
- Value-based / Model-based: 基于数据/模型
之所以有这么多的算法,主要是各方面的权衡,涵盖:数据收集、监督信号的种类、行为空间的连续性等等……