梦开始的地方:Attention Is All You Need
本文不再介绍背景等信息,而是重点关注具体算法与实现
注意力分数指的是:对于一个输入 Q,通过和 K 计算某种关系,得到 V 的权重,最后权重乘以 V 得到最后的分数
举个例子,对于这个公式,其中 α(x,xi) 是注意权重,−21(x−xi)2 表示的是注意力分数:
f(x)=i∑α(x,xi)yi=i=1∑nsoftmax(−21(x−xi)2)yi
上式是计算 x 的注意力分数的公式,表示输入 当前输入 x 去和一组记忆位置 xi 做相似度比较,得到权重
α(x,xi),再用这些权重对对应的 yi 加权求和。
直观理解就是,如果 x 和 xi 非常近,那么对应的权重就会上升,所以对应的输出就会更大
扩展到向量后,形式几乎不变,但是差平方替换为向量的平方范数 ∥x−xi∥2=∑m=1d(xm−xi,m)2 ,也就是所有维度的差的平方求和:
f(x)=i=1∑nαi(x)yi,αi(x)=∑j=1nexp(−21∥x−xj∥2)exp(−21∥x−xi∥2)
上式就是带入了一个 Softmax 的结果
最终的目标是缩放点积注意力公式
Attention(Q,K,V)=softmax(dkQK⊤)V
1 个 query:q∈Rdk,n 个 key:k1,…,kn∈Rdk,对应 n 个 value:v1,…,vn∈Rdv
- 计算 query 和每一个 key 的相似度,也就是 si=q⋅ki=q⊤ki,也就是点积,越大表示向量方向越近
- 缩放:s=[s1,s2,…,sn] 执行缩放后为 s~i=dksi ,也就是对维度缩放一下
- Softmax:计算成概率权重,αi=∑j=1nes~jes~i 得到一组权重(就是注意力分数)满足 α1,α2,…,αn,αi≥0,∑iαi=1
- 加权求和:o=∑i=1nαivi
- 点积对于多个 query 和 key,可以用矩阵并行化一次运算完毕
- 本身具有相似度的含义:q⊤k=∥q∥∥k∥cosθ
一个很常见的八股文问题,需要掌握数学推导
如果 q 和 k 的每个分量都大致是均值 0、方差 1 的随机变量,那么点积 q⊤k=∑m=1dkqmkm 是 是 dk 项的求和
如果每一项的方差大致是 1,那么总方差会随维度增长,大约是:Var(q⊤k)∝dk
关于高斯方差累计,对于独立的随机变量有 Var(∑i=1nXi)=∑i=1nVar(Xi)
Softmax 对输入的尺度非常敏感,所以大方差会导致指数迅速拉开差距,方差大后几乎会退化成 one-hot 的形式
对 Softmax 计算梯度得到
pi=∑jezjezi,∂zk∂pi=pi(δik−pk)
其中 δik 在 i=k 等于 1,否则为 0,对于尖锐的 Softmax 有 pm≈1,pj≈0 (j=m)
代入得到:
- 对最大那个位置:∂zm∂pm=pm(1−pm)≈1⋅0=0
- 对其他位置:∂zj∂pj=pj(1−pj)≈0
- 交叉项:∂zk∂pi=−pipk≈0
整个 Softmax 的雅可比矩阵几乎全部都是 0,这也就是梯度消失
尤其注意一下这里的维度变化
对于输入的 Q∈Rn×dk,K∈Rn×dk, V∈Rn×dv 三个矩阵计算 Attention:
- 计算分数矩阵:S=QK⊤ ,其中S∈Rn×n, Sij=qi⊤kj (就是一维的值分布到了各个矩阵位置上)
- 缩放:S^=dkS
- 有时候还会有掩码,也就是不允许看到未来的 token,负无穷到 softmax 分子是 0:
S^ij={S^ij,−∞,允许关注不允许关注
-
Softmax:对每一行做 A=softmax(S^) ,这里没有发生维度变化A∈Rn×n,只是改成了概率分布
-
输出:O=AV,其中O∈Rn×dv ,oi=∑j=1nAijvj 表示第 i 个位置从全序列汇总得到的新表示
实际上输入最基本的维度要求是这样的:
-
Q∈Rnq×dk
-
K∈Rnk×dk
-
V∈Rnk×dv
主要有两点要求:
- Q 和 K 的内积维 dk 必定相等,因为要做点积
- K 和 V 序列长度 nk 必须一样,但是特征维度dk dv可以不相同
因为每一个行对应一个 query, [Si1,Si2,...,Sin] 表示第 i 个 query 对所有 key 的打分
自注意力指的是,所有的 QKV 都来自与一个 X
对于序列长度是 n,每个 token 的输入表示维度是 dmodel,有输入矩阵X∈Rn×dmodel
将输入经过三个投影矩阵计算后得到:
Q=XWQ,K=XWK,V=XWV
各自的维度是: WQ∈Rdmodel×dk, WK∈Rdmodel×dk, WV∈Rdmodel×dv
后续的算法都是跟矩阵形式是一样的了
而 交叉注意力唯一的区别就是:
Q=X1WQ,K=X2WK,V=X2WV
普通的单头注意力只有一套 WQ,WK,WV,因此只能在一个子空间里做一次注意力匹配,一次只能学习到一次关系模式
但是在同一句话中模型需要同时关注多种关系,因此可以投射子空间来强化理解能力
多头注意力的做法是把 Q,K,V 分别投影到 多个不同的子空间,每个子空间各自做一次注意力,最后再拼接起来。
对于输入 X∈Rn×dmodel,头数 h,每个头的维度 dk=dv=dmodel/h(注意这里 Q 和 K 的最后一维必相同),第 i 个头有:
headi=Attention(Qi,Ki,Vi)
其中:WQ(i)∈Rdmodel×dk, WK(i)∈Rdmodel×dk WV(i)∈Rdmodel×dv 计算得到
Qi=XWQ(i)∈Rn×dk,Ki=XWK(i)∈Rn×dk,Vi=XWV(i)∈Rn×dv
计算注意力权重:
Ai=softmax(dkQiKiT),QiKiT∈Rn×n
因此每一个头都有自己的注意力矩阵,每个头运算得到结果:
headi=AiVi∈Rn×dv
执行矩阵拼接得到 H=Concat(head1,…,headh)∈Rn×(hdv) (也就是第二个维度执行左右拼接),最后乘以输出矩阵WO
目的是把所有头拼接后的结果再映射回模型维度,得到 Y∈Rn×dmodel
Y=HWO,WO∈Rhdv×dmodel
这里 WO 类似于整合作用,把所有的信息混合到一个统一的表示
Attention 架构中无法感知所有 token 之间的顺序,因此需要位置编码结合到 Embedding 中,让模型感知到 token 的位置
一般而言:对一个 token 的向量xi∈Rdmodel,加入位置编码后成为 zi=xi+PE(i)
总体而言 PE 分为两大类,绝对位置编码和相对位置编码
绝对指的是,0123 这种绝对位置,Attention 论文中用的就是固定的正余弦位置编码;相对指的是表达两个 token 之间的相对位置
在论文中定义 PE 为下式,其中pos是位置,i是维度索引的一半,dmodel是模型维度
PE(pos,2i)=sin(100002i/dmodelpos)
PE(pos,2i+1)=cos(100002i/dmodelpos)
- 最基本的:不同的位置可以得到不同的值,这可以区分位置
- 编码具有连续性:位置相近则编码结果相似,距离远则位置更远
- 可以学习相对位置:sin(a+b),cos(a+b) 可以通过由 sina,cosa 与偏移量 b 的关系表示(三角和公式)
- 可以外推:因为是公式生成的,所以扩展到训练中没有见过的更长位置
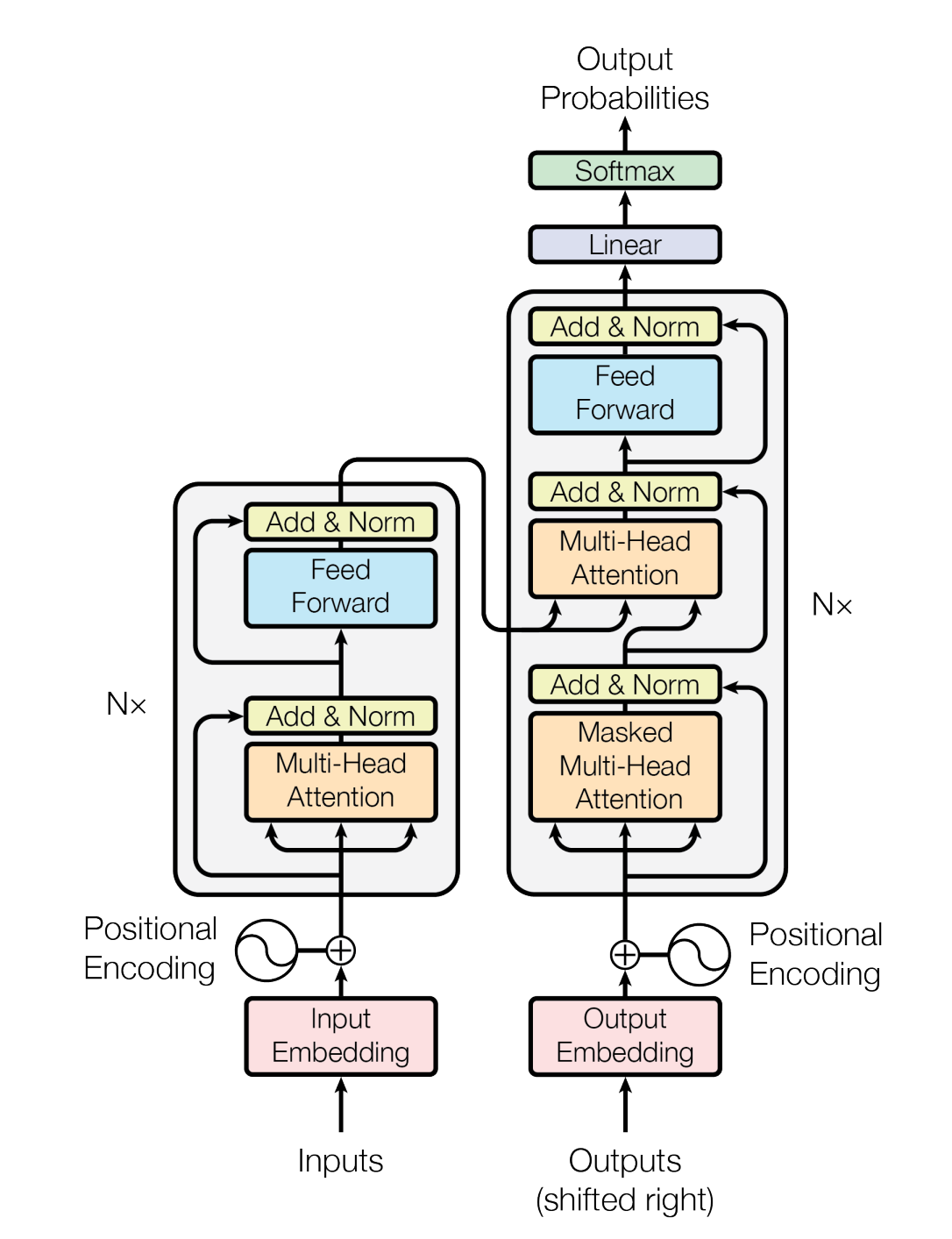
指的是 Embedding + Position Encoding 向量模块,整体流程是:
- tokenizer 将整个句子切分一下,常见的方式有 BPE 组合
- Embedding,将每一个 token 映射为一个向量 xi∈Rdmodel,隐藏维度 dmodel,序列长度n
- PE 加到 Embedding 结果中:Z=X+PE, Z 是 Encoder 的输入
在论文中超参数 dmodel=512
整个 Encoder 包括以下这些结构,构成一个 Block,在论文中是堆叠了 N=6 次
- Multi-Head Attention(是 Self-Attention)
- Add & Norm
- Position-wise Feed Forward Network
- Add & Norm
Transformer 各个层的序列的长度和维度全都不变,隐藏维度也保持不变,所以很方便堆叠很多层
使用 Self-Attention 实现的 MHA,QKV 来自于同一个 X,也就是上文中的 Z
先执行线性映射,对输入映射到 Q=XWQ,K=XWK,V=XWV
然后按照 MHA 流程切分到h个头(论文中超参数 h=8),每一个头计算 headh=softmax(dkQhKhT)Vh
最后执行拼接 MultiHead(X)=Concat(head1,…,headH)WO ,输出维度仍然是:Rn×dmodel
残差连接(Residual Connection)+ 层归一化(LayerNorm):
LayerNorm(X+Sublayer(X))
其中 Sublayer(X) 是上一个 MHA 的变换后的输出结果
Layer Norm 算法指的是,对于 x=[x1,x2,…,xd] 序列计算均值和方差:μ=d1∑i=1dxi, σ2=d1∑i=1d(xi−μ)2,执行归一化:
x^i=σ2+ϵxi−μ
其中 ϵ 是一个很小的数,防止除零。之后再使用一个可学习的额缩放和平移:
yi=γix^i+βi
作用是先执行标准化,之后再让模型学习一个更加合适的分布
为什么用 Layer Norm 而不是 Batch Norm 也是个很常见的问题,这里省略
残差连接的功能是帮助梯度传播,减轻网络太深导致的退化问题。(为什么呢?)
前馈网络,指的是对每一个位置做一个相同的 MLP
FFN(x)=max(0,xW1+b1)W2+b2
原论文用的是两层线性层,中间 ReLU,第一层:从 dmodel 升到 dff;第二层:从 dff 降回 dmodel,就是一个多层感知机,论文中这个超参数 dff=2048
Attention 的作用是 token 之间的信息交互,FFN 的作用是让 token 与对自己的做非线性变换
在 FFN 后接一个残差连接,承接作用
Decoder 也是堆叠 N=6 层,但每层比 Encoder 多一个注意力模块,包含(这里把 Add & Norm 结合到上一层了)后文省略 Add & Norm:
- Masked Multi-Head Self-Attention + Add & Norm
- Encoder-Decoder Attention(Cross-Attention)+ Add & Norm
- Feed Forward + Add & Norm
因为 Decoder 不仅仅需要自己的生成信息,还需要输入句子的相关信息,SA 负责看已经生成的 token 的信息,CA 负责查看 Encoder 的内容
Decoder 的输入是当前输入的是将目标整体向右移动一位的输入,也就是:
对于目标:
<bos> 我 喜欢 学习 Transformer <eos>
Decoder 的输入是:
<bos> 我 喜欢 学习 Transformer
Decoder 的期望输出和监督目标是(<bos>是启动生成的编码):
我 喜欢 学习 Transformer <eos>
因为模型不应该看到预测的目标,所以这里会出现一个 Mask 部分,实际上就是累加一个下三角矩阵 M :
Mij={0,−∞,j≤ij>i
回顾一下 负无穷在 Softmax 的输出就是 0,这保证了 Decoder 的输出是自回归的,不依赖未来
Decoder 相对于 Encoder 最大的区别在这里,这里的 Q 来自 Decoder 当前隐状态,但是 K,V 来自 Encoder 输出:
Q=HdecWQ,K=HencWK,V=HencWV
Henc:Encoder 最后一层输出的整段序列表示,Hdec:Decoder 在进入 cross-attention 前的输入表示
注意这里WQ,WK,WV是这一层 cross-attention 自己学习的参数,不是 Encoder 中缓存的 KV
CA 作用是让 Decoder 在生成的时候会额外考虑输入句子的相关内容,类似于Decoder 在边生成边对输入做检索
最后在输出的地方执行 FFN + Add & Norm 步骤,作用同样是 token 与自己交互
Decoder 最后一层的输出是 Y∈Rn×dmodel ,通过一个线性层,映射到词表中:
logits=YWvocab+b
对于词表大小是 V,则有:logits∈Rn×V
最后对每一个位置执行 Softmax 可以计算出每一个词语的概率:
P(yt∣y<t,x)=softmax(logitst)
论文中没有直接提出这个,但是这是一个非常常用的工程优化方案
对于一个 Decoder 生成中过程,假设已经生成了: y1,y2,y3 现在开始预测 y4
没有 Cache 的 Decoder,那么会把整个序列 [y1,y2,y3], 重新送进模型,再算一次 self-attention。
等要预测 y5 时,又把:[y1,y2,y3,y4]整个再算一遍,于是前面那些 token 的 K,V 会被重复计算很多次。
KV Cache 的核心思想是:历史 token 的 Key 和 Value 一旦算出来,后续生成时就不变,缓存起来复用。
(感觉有点像 DP 里面的记忆化搜索hhhh,简而言之就是缓存减少重复运算)
对于某一个 Decoder 中的某一个 Attention 模块,有隐藏状态:X∈RT×dmodel, 经过线性映射得到:
Q=XWQ,K=XWK,V=XWV
经过 MHA 以及多 Batch 得到:Q,K,V∈RB×H×T×dhead
KV Cache 就是缓存每一层历史里的历史位置:Kpast,Vpast,
也就是: Kcache∈RB×H×Tpast×dhead , Vcache∈RB×H×Tpast×dhead
如果是在 Transformer decoder 推理 里做 KV cache,缓存空大小:
Cache bytes=N×(需要缓存的 attention 模块数/层)×2×B×n×bytes_per_elem
- 层数:Decoder Block 个数,经典值 N=6
- Attention 个数:也就是每一个 block 有几个 Attention 模块
- 2 :这个 2 指的是 KV 各要一份缓存空间,所以一个 Attention 模块是 2 份
- B:Batch Size
- n :序列长度
- bytes_per_elem:每一个数据的结构大小
实际上严谨一些的话也不完全对,在 Decoder 架构中的 SA 和 CA 的长度并不一致:
SA 缓存的是 decoder 已生成序列,长度是 n;CA的 K,V 来自 encoder 输出,长度应该是源序列长度,记为 m
更加严格的写法是:(2nd+2md)×B×N×(需要缓存的 attention 模块数/层)
