
ViT
首先补充一点 ViT 的知识,需要一点点 BERT 的知识前置
Vision Transformer 是多模态相关的一个核心论文,也是 CLIP 中使用的 image encoder
论文全名:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
这篇文章发布于 2020 年,主要工作就是如题目所展示的,将 Transformer 架构应用到了视觉图像领域
如果将 Transformer 直接完整复制到 图像领域有以下几点困难:
- 计算复杂度, 原生的 self attention 计算复杂度对于图片的像素数量是非常大的
- CNN 有 平移不变性和局部结构功能,但是 Transformer 这些能力都没有,泛化性可能下降
- 视觉的 2D 结构如何能够使用 1D sequence 表示呢?
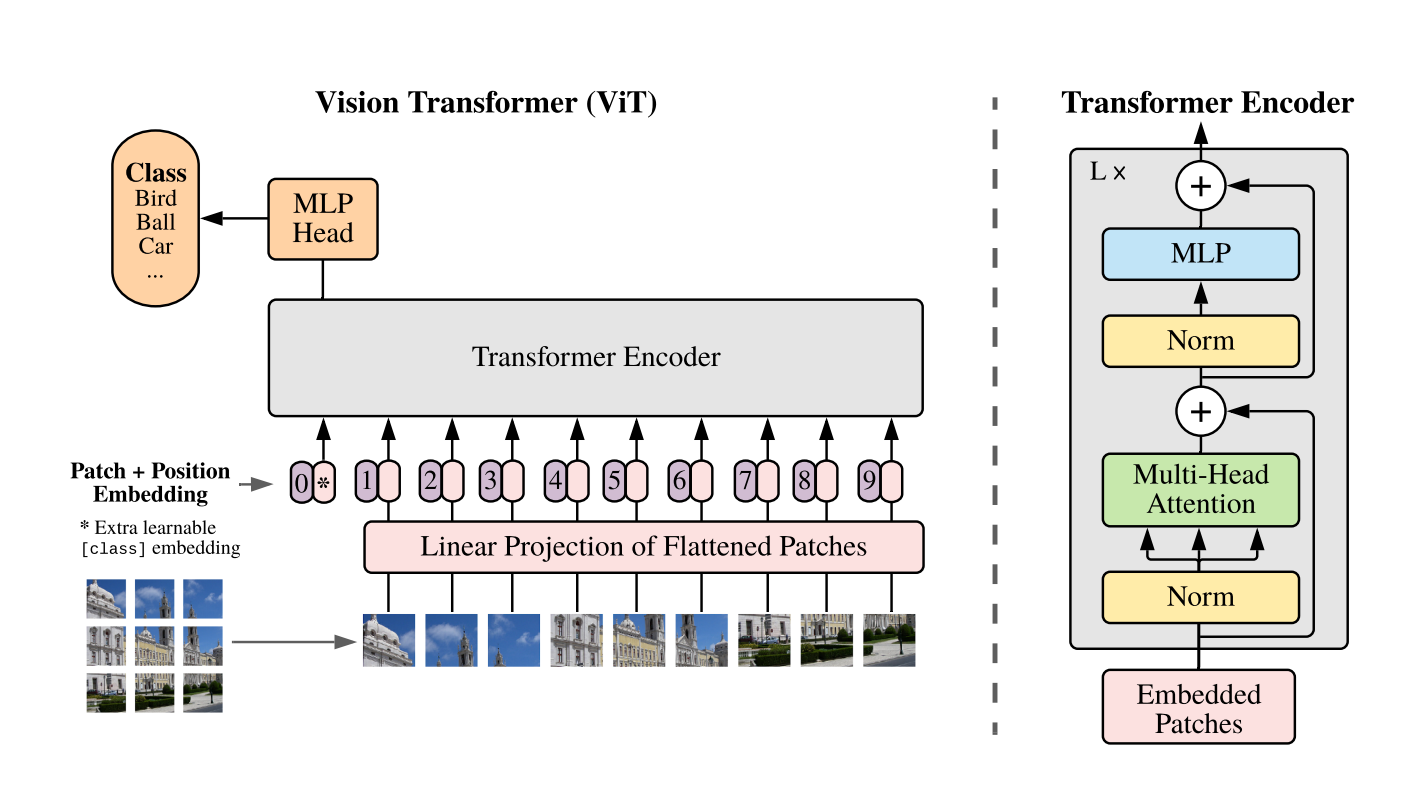
Patch Embedding
Section titled “Patch Embedding”如上图所示的主要架构,作者将一张图像切分为 Patch 格式,也就是类似于 sentence 切分到 word 一样
对于输入图像 设置 参数 表示一个 patch 的边长,切分一张图得到 个 patch
切分完毕后,将 2D 图像 flatten 到一个一维向量,再通过 linear projection 执行 embedding,类似于将一个 patch 编码成了一个 token
[CLS] token
Section titled “[CLS] token”一个 BERT 中的设计,引入了一个 [CLASS] 的 token,这个 token 不断和所有的 patch 交互来整合全局的信息
也就是 ,这个 token 在 encoder 的输出状态就是整个图像的表示
在 Transformer 编码器输出中,第 L 层(最后一层) 第 0 个 token 的状态(也就是最后一层的 [CLASS] ),经过了层层的更新,可以代表整个图片的信息
在后面,作者指出对 最终图像的表示就是 , 也就是对这个 token 执行 Layer Norm
Position Embedding
Section titled “Position Embedding”在这里 ViT 使用的是普通的 1D 位置编码,因为作者发现 2D 实际上没有什么显著的效果
注意这里不是 RoPE(那个时候 RoPE 还没有被发表,后续工作有的用 RoPE),而是普通的 standard learnable 1D position embeddings,这是一个普通的可以学习的编码
这就会有一个坑,因为位置编码都是固定的,所以更换分辨率会产生问题,作者指出直接使用插值来弥补一下
Transformer Encoder
Section titled “Transformer Encoder”Encoder 使用的是标准的架构, 也就是 Multi-head Self Attention + MLP + LN + Residual
这两个公式,一个是算基础的 MSA,第二个就是残差连接,详见 Transformer 的原文架构
最后输出的分类头就是 , 送进 MLP 算出最后的结果
作者首先在 大数据上执行 pretrain,随后在小数据上微调。
实验结论表明,如果使用大数据,那么其效果是超过 CNN 的,但是小数据集的效果会不如 CNN
这篇文章最主要的贡献,是允许把一个图像用序列的方式表示出来,这也是后续图像多模态的基础
论文全名: Learning Transferable Visual Models From Natural Language Supervision
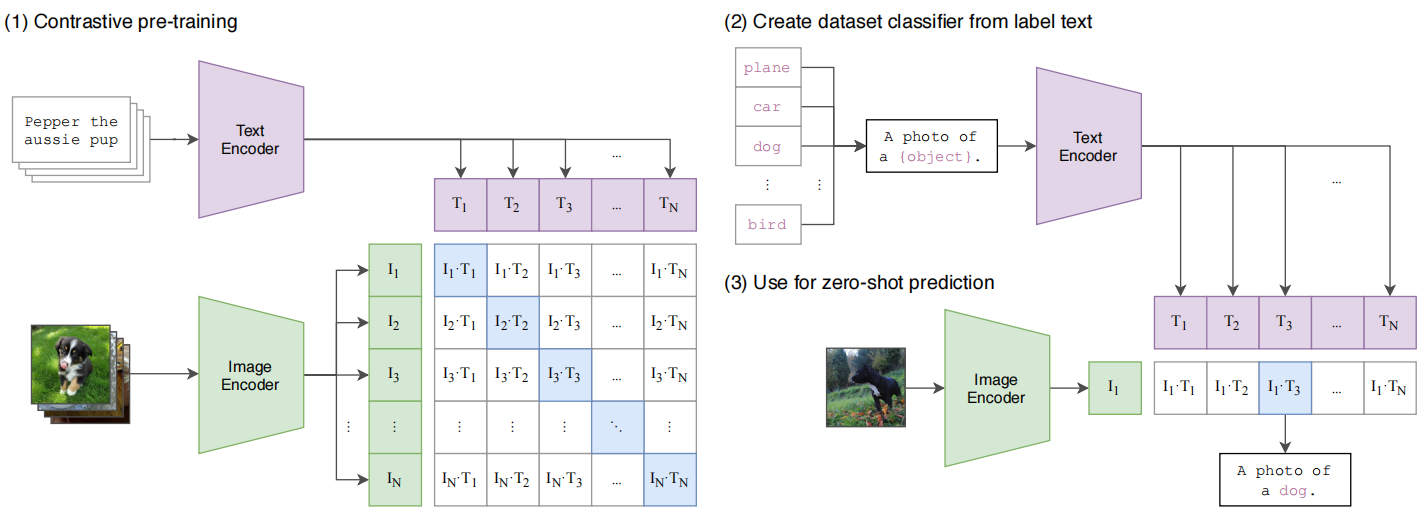
-
Pretrain: 通过自然语言处理来获得一个从视觉模型中迁移,从 image encoder 上获取特征,然后和 text encoder 上执行特征匹配,然后进行对比学习:在对角线上的就是正样本,而非对角线上的就是负样本
-
Classifier: 把分类标签嵌入到一个 prompt 变成 “A photo of a xxx” ,然后通过 text 编码器可以得到 文本的 embedding 数据
-
Prediction: Zero shot 预测,输入一个图像经过 image encoder,去算 cosine 相似度然后得到最后的语句输出,也就是分类
这里的标签也是可以改动的,这是非常强大的地方,因为摆脱了 Category Label, 可以输入任意的标签执行 encoder 就行了,可以是训练数据集之外的内容,只要 encoder 的 text label
基于 CLIP 可以做非常多的工作,包括最经典的传统的图像分割,图像分割等
主要就是以下几个问题
-
准备一个超级大的数据集,400 million 的文本对,使用自然语言(因为自然语言的迁移性很好)
-
Image + Text 两个 encoder 执行,计算出对应的 feature
-
两个 feature 通过 embedding 映射到同一个空间中,使用的是线性层
-
最后构造出了一个矩阵,矩阵的对角线上就是正确的图文对,非对角线则不匹配,训练目标就是让对角线的值最大
这里说一下对角线的值就是,横纵向都做 softmax,然后让匹配的那个值在两个 softmax 中都最大
为什么使用对比学习
Section titled “为什么使用对比学习”- 词汇都来自于互连网,没有固定的类别,不是一个确定的词可以指定,只用 label 会导致信息额外的丢失,而且数据相对 noisy,成本不允许
另外 label 化也会丢失一些自然语言信息,例如:“a small brown dog running on grass” 就只剩一个 “dog” 了
- 对比学习有非常好的分类可迁移性,对于自然语言的分类,例如 “a cat” 和 “the dog” 这种都可以学习到其中的隐藏特征,不需要重新训练分类器
- 训练效率高,对于 N 的 batch size 都可以产生 个对比样本,效率很高
总结而言,CLIP 的目的不是为了做类别的预测,而是判断文本和图片是否匹配,学习的是一个 一个共享的图文语义空间
什么是双塔模型
Section titled “什么是双塔模型”双塔就是两个独立编码器结构, Image + Text,最终让图像和文本映射到同一个 embedding 空间中
Image Encoder:作者尝试了 ResNet, ViT (Vision Transformer)
Text Encoder: 作者使用了 Transformer + BPE 编码