回顾一下之前的章节,我们主要学习了 3 种梯度相关的方法:
- 蒙特卡洛,直接从数据轨迹中学习策略
- Bootstreapping,允许在旧的轨迹上估计新的策略的 value function
- Q learning,不再使用 value function 评估,而是直接学习 Q 作为策略目标
具体来说,可以将算法分成 online / offline, on-policy / off-policy:
- Online: agent 可以和环境事实交互,可以用新的策略采样到新的数据,根据新策略进一步更新策略
- Offline: 一个固定的数据集,不再实时的交互,最大的问题就是不可以探索,一旦出现未出现的动作效果就会很差
- Off-policy: 指的是学习的策略和采样数据的策略不相同,比较经典的就是 DQN,或者使用了 replay buffer 采样的数据可能不是当前的策略的数据,off-policy 的缺点是数据分布和目标策略不一致,导致估计有偏或方差变大。
本章主要讲 offline RL,offline 主要用在高数据成本的情况下,例如智能驾驶中让 agent 真的去驾驶一辆车代价很昂贵。
offline RL 不能简单地直接套用普通 off-policy actor-critic / Q-learning。
考虑 off-policy critic 的 Bellman 回归目标:
ϕmin(s,a,s′)∼D∑Q^ϕπ(s,a)−(r(s,a)+γEa′∼πθ(⋅∣s′)[Q^ϕπ(s′,a′)])2
它的意义是 当前状态动作的价值 = 当前奖励 + 下一状态按照当前策略继续行动的未来价值
首先 offline 的数据来源是固定的,也就是说可能不会包含一些范围的数据,但是 Q function 的输出是是随机初始化的,一旦这个随机值很高,并且后续的 offline 数据集中也没有这个行为来进行纠正,那么就会一直保留这个值。
在这个式子中,一旦策略更新后, a′ 就有可能会出现不在数据集中的行为,就好比智能驾驶数据集中没有出现高速掉头或者倒车的情况,这就很危险了。
称为 Advantage-Weighted Regression (AWR)
之前章节讲过模仿学习的相关内容,在离线学习中可以参考模仿学习的一些内容。
在模仿学习中中会平等的学习所有的动作,但是在离线数据集中的动作有好坏之分,可以需要区分一下。
使用的方法就是 advantage function 来给动作加权:
θ←argθmaxEs,a∼D[logπθ(a∣s)exp(A(s,a))]
logπθ(a∣s) 是模仿学习的标准式子,后面使用 exp(A(s,a)) 对行为进行加权。
为了不然让新的策略偏离旧的策略太远,我们可以使用:
πnew=argπmaxEa∼π(⋅∣s)Q(s,a)s.t.DKL(π∣∣πβ)<ϵ
这里的优势函数依旧可以使用之前章节中的蒙特卡洛或者 Bootstrapping 算法来估计,在使用离线数据集的时候蒙特卡洛的算法甚至会更加简单,因为不需要考虑方差等问题。
此时完整的算法流程如下:
- 训练一个价值函数 V(st) ,目标是估计 Gt=∑t′=tTr(st′,at′) 从当前到轨迹结束的累计回报。
算法使用的是蒙特卡洛,也就是一个监督学习,目标公式
ϕminst∼D∑V^ϕπβ(st)−t′=t∑Tr(st′,at′)2
- 使用加权训练策略:
θmaxE(st,at)∼D[logπθ(at∣st)exp(α1(t′=t∑Tr(st′,at′)−V^ϕπβ(st)))]
这里 α 控制 advantage 的敏感度,更大的 α 会导致更加倾向于高 advantage 动作。
但是蒙特卡洛也有问题,计算 Aπ(s,a)=Qπ(s,a)−Vπ(s) 的时候,这里后续的轨迹都来源于数据集中,也就是 behavior policy πβ, 而不是当前优化的目标 πθ,所以这个算出来的结果是 这个动作相对于旧策略 πβ 来说好不好。
我们可以尝试使用 TD update 来替换 Monte Carlo 算法,但是会引入额外的问题,Q 函数需要查询 OOD action。
回顾一下经典的 Bellman 回归算式:
ϕminE(s,a,r,s′)∼D[(Q^ϕπθ(s,a)−(r+γEa′∼π(⋅∣s′)[Q^ϕπθ(s′,a′)]))2]
算式中 a′∼π(⋅∣s′) 的行为是从当前策略 πθ 中采样出来的,所以可以解决上一节蒙特卡洛中 πβ 和 πθ 的问题。但是问题也恰恰出在这里。
这里的 a′ 是从当前策略 πθ 采样的。但当前策略 πθ 不一定只输出数据集中出现过的动作,也就是 Out Of Dataset (OOD)。
所以这就是一个很关键的 trade-off:
- 想要超过数据集策略 πβ,就需要评估新策略 πθ 的动作。一旦超出数据集分布,Q 函数就可能不可靠。
- 想要解决 OOD 的分布问题,就会导致 policy 的提升会受到 πβ 的限制。
普通 TD update 更新 Q 使用下式:
Q^πβ←argQminE(s,a,s′,a′)∼D[(Q(s,a)−(r+γQ(s′,a′)))2]
可以看到当前状态和下一个动作都来自于数据集,也就是 (s,a,s′,a′)∼D,这样就能修复 OOD 问题
IQL 的核心算法是在不 OOD 的情况下,尝试估计一个比 πβ 更好的策略的 Q
参见下图表示在同一个状态 s 下,不同数据集动作的 Q(s,a) 分布。
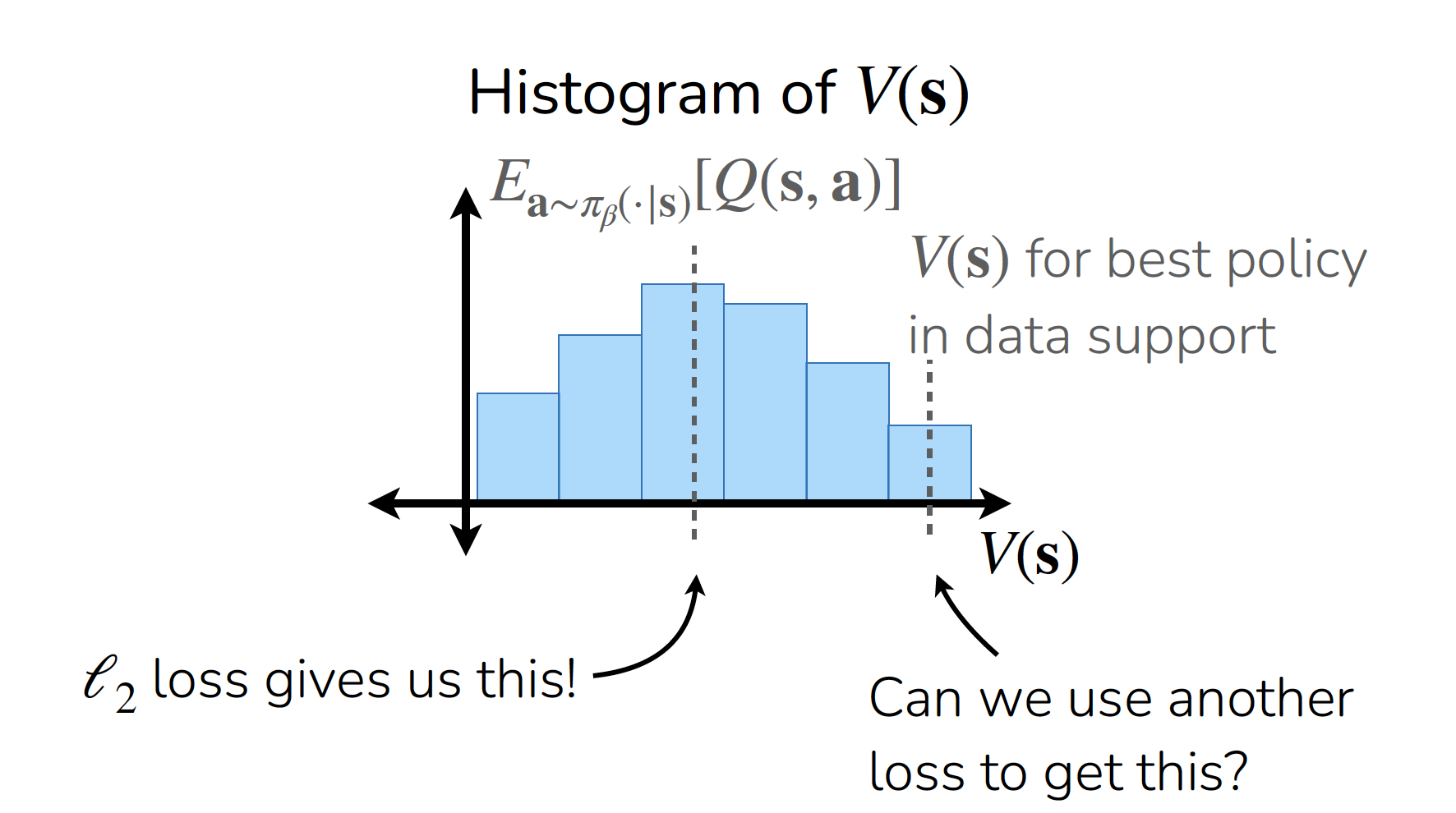
如果对此使用普通的 L2 Loss 拟合 value function 则会得到 Ea∼πβ(⋅∣s)[Q(s,a)],也就是 πβ 的平均值,对应就是数据集策略的水平。
如果能够改变 Loss 让 value function 更加偏向于更高价值的动作,就可以鼓励 agent 选择更高价值的行为,但是不可以直接用 MAX 取值,因为这个分布中可能会包含 OOD 的数据。
因此最后通过改变 Loss 让 Value 估计值倾向于数据集中的高价值工作,具体的非对称 Loss 方程不在这里介绍。
- 首先使用非对称的 Loss 拟合 value function:
V^(s)←argVminE(s,a)∼D[ℓ2λ(V(s)−Q^(s,a))]
其中
ℓ2λ(u)=∣λ−1(u<0)∣u2
- 使用普通的 TD loss 来更新 Q(s,a)
Q^(s,a)←argQminE(s,a,s′)∼D[(Q(s,a)−(r+γV^(s′)))2]
- AWR 算法更新策略:
π^←argπmaxEs,a∼D[logπ(a∣s)exp(α1(Q^(s,a)−V^(s)))]
也就是说 IQL 算法中需要同时训练三个函数:
Qϕ(s,a),Vψ(s),πθ(a∣s)
其中训练 Q,V 的阶段只使用离线数据集 D ,随后可以用这两个结果计算 Advantage,然后把他变成权重,用来对 policy 执行 AWR 训练。
